こんにちは、@shuhei_fujiwara です。
技術書典5から会場を変更し、参加サークルも約246から470超(企業スペースを含め調整中です)と劇的に増加しました。元々サークルの配置決めは非常に時間が掛かっていた作業ですが、さすがに今回は手動では乗り切れない規模になりました。運営事務局は指数的に増えていくサークル配置の組合せを見て絶望に包まれていました。
そこで技術書典5からサークル配置の(半)自動化を検討することになり、@shuhei_fujiwaraが実装を担当しました。
ことのあらまし 僕自身も今回から配置作業に参加して知ったことですが、技術書典はちょっと引くくらい配置にこだわっています。考慮すべき制約は大量にあるのですが、大まかな方針としては以下の3つに気をつけて配置を決めています。
近いジャンルのサークルが同じブロックに集まるように
ジャンルの境界でなければ両隣のサークルのジャンルには気を配る
特に珍しいジャンルのサークルの同志は近くに集まるようにする
1と2が自明なのに対し、3は見落としがちですが重要な制約です。技術書典が技術の良い出会いの場所であるために、これは可能な限り実現したい ポイントでした。
検討段階では機械学習で配置を何とか改善したいという要望から出発しましたが、最終的には数理最適化ベースの手法へ落ち着きました。機械学習を採用しなかった背景は機械学習で扱える問題に落とし込む難しかったということと、前述のように珍しいジャンルを見落とさずに扱うのが難しいだろうという判断でした。
半自動配置の手順 技術書典では、ざっくり次のような手順で行っています:
全サークル間の類似度を定義する(定義の仕方は後述)
良い感じのアルゴリズムでサークルをグループに分割する
各グループ内での配置順を決めて通し番号を付与する
グループ単位で配置場所を決定、人間が動線を考慮して調整する。この時点で叩き台となる
配置単位で調整をおこない、最終版が完成する
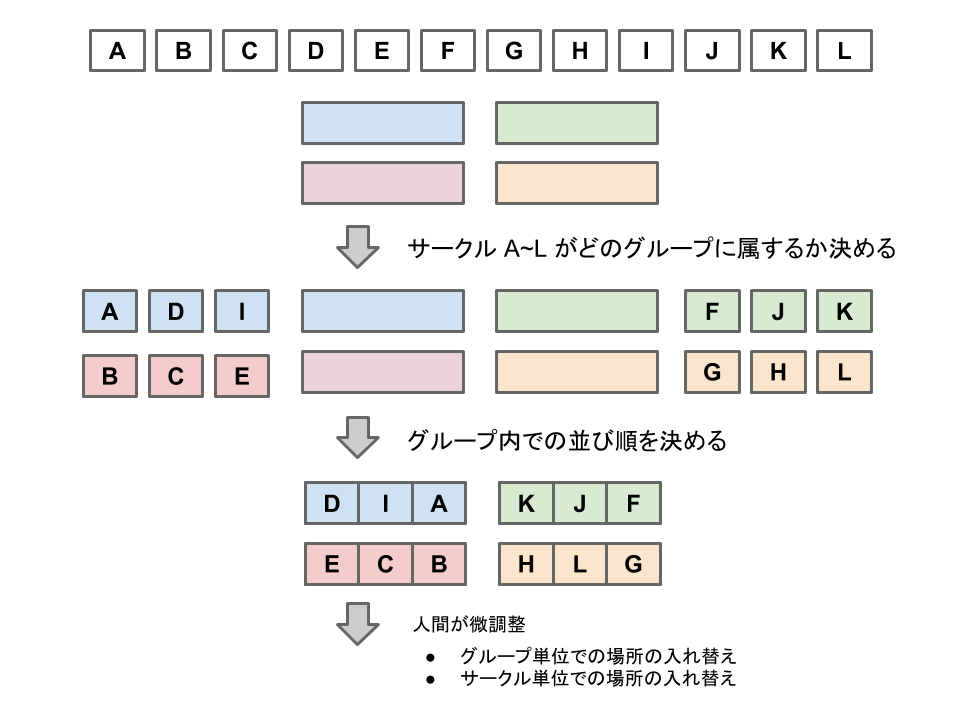
今回は手順3までを自動化し、手順4以降で人間による調整を行っています。各工程のうちグループ分割を行う手順2と配置順を決定する手順3は補足が必要です。少し分かりにくいかもしれませんが、以下の図のようなイメージです。
手順2のグループ分割は各サークルがどのブロック(ブロックとは「あ-X」のように同じひらがなでまとめられる集団を指した自動化用の概念です)に属するかを決める作業です。実際には会場の形を考慮して会場の配置区分(あ、い、うなどで表現されているもの)よりも細かく分けました。グループ分割の工程では、グループ内のサークル間類似度の総和が最大になることを目標とします。
手順3の配置順の決定とは、具体的にグループ内での各サークル配置順序を決めていきます。会場の形状に依存しますが同一グループは基本的には一直線上に並ぶことを仮定して、サークルの両隣との類似度の総和最大化を目標とします。
技術書典4では手順4の叩き台と同程度のものができるまでに丸々2日 掛かっていましたが、2時間程度 (ただし@shuhei_fujiwaraの工数を除く)で可能になりました。サークル数が倍近くに増えたにもかかわらずです!
浮いた丸2日をすべて投入し、今回は前回以上に細かい調整を行いました!あれ?何か楽になってなくておかしいぞ…?
アルゴリズムの詳細 サークル間類似度の定義 各サークル間の類似度を機械的に計算するために、まずはサークルごとに次のようなジャンルのタグづけを行います。
tag1
tag2
tag3
tag4
tag5
サークル1
機械学習
数学
R
サークル2
機械学習
ハードウェア
IoT
数学
…
…
…
…
…
…
サークルN
Android
IoT
iOS
タグはスタッフがジャンル詳細を見たり、各サークルのホームページや記憶を漁って人力でつけています。
※編集注:技術書典では自動化にかかるコストと得られるパフォーマンスをかなりキチンと判定しています。初回が手作業であっても施策に効果があれば自動化していき、どんどん工数を浮かせて、浮いた分を別の企画や改善につぎ込んでいきます。
サークル間の類似度はタグの集合同士の類似度という形で定義します。
共通のタグを持っている集合同士は類似度が高い
珍しいタグを持っている集合同士は特に類似度が高い
タグをたくさん持っている集合が極端に有利になることを避けたい
まずは集合間で共通要素があったときのスコアを定義します。「機械学習」というタグが共通要素として存在していた場合のスコアは今回では次のように定義しています。
1 1 / (log [機械学習タグを持つサークルの総数] + 1)
複数のタグが共通している場合はスコアが一番高いもの(つまり一番珍しいタグ)を使って計算し、これを集合間の類似度としています。
たとえばサークル1とサークル2の類似度を計算する場合は {機械学習, 数学, R} 集合と {機械学習, ハードウェア, IoT, 数学} 集合の類似度を考えます。{機械学習, 数学} なので次のように類似度を計算できます。
1 2 3 4 similarity = max( 1 / (log [機械学習タグを持つサークルの総数] + 1), 1 / (log [数学タグを持つサークルの総数] + 1) )
このとき、次の条件(配置上の気持ち)を反映させるために定義しています。
タグが多いサークルが極端に有利になることを避けたい
珍しいタグが共通している場合は類似度が高くなるようにしたい
こなれておらず、まだ変更の余地がある部分なので次回はもう少し調整するかもしれません。
なにはともあれ類似度を定義したので次のような類似度表を得ることができました (数値は実際のものとは異なります)。
サークル1
サークル2
…
サークルN
サークル1
—
0.3
…
0
サークル2
0.3
—
…
0.5
…
…
…
…
…
サークルN
0
0.5
…
—
グループ分け問題の定式化と解法 前述までに定義し、算出した類似度を元に似たサークルが集まるようグループ分けを行います。ここでいうグループは「あ-X」のような同じひらがなで括られるようなブロックに近いものですが実際には会場の形を考慮してもう少し細かくするなどの調整を行い、最終的にはだいたい20サークルずつのグループに分けることにしました。
少し手を抜いた表記ですが、次のように同じグループに属しているサークル間の類似度の総和を最大化することがゴールになります。
y_i_j はサークルiとサークルjが同じグループに属していれば1、そうでなければ0とします。
s_i_j はサークルiとサークルjの類似度です。
各グループには次のような制約があり、この制約下で前述の目的関数を最大化していきます。
グループごとに収容可能なサークル数の上限が存在する
サークルは1つのグループにしか所属することができない
最適化アルゴリズムは「ランダムにサークルを配置したあとグループ間でサークルの交換を検討し、目的関数値が改善するならば交換を行う」というシンプルなものを採用しました。数理最適化出身の人間として、ここはいずれもっと良いものを用意したいなと密かに考えています。
グループ内配置の定式化と解法 グループ分けが済んだら今度はグループ内での配置を決定します。グループ内で各サークルは一直線に並ぶという仮定をおき、今度は両隣のサークルとの類似度の総和が最大になるような並び順を求めるという定式化をしました。
ここもアルゴリズムは同様で、ランダムに並び順の入れ替えを検討して目的関数値が改善するなら並び替えを実行するという手法で実装しています。
1 2 3 @vvakame 「グループ分け良い感じなんだけど、グループ内の細かい配置もないとつらくない?」 @shuhei_fujiwara 「次回までに欲しいですね」 @vvakame 「明日までに欲しくない?」
NG集 結果としてはかなりシンプルな方法になりましたが、ここに着地するまでにそれなりの紆余曲折があったのでNG集をお楽しみください。
サークル数500程度なら整数計画問題を解き切れるのでは?
それなら連続緩和して適当に丸めればなんとかなるのでは?
緩和したら完全にダメなタイプの問題でした
1つのサークルが小数点以下の単位に細かく千切られてすべてのブロックに配置されていきました
せめてグラフの問題に落とし込みたい
量子コンピュータってやつでなんとかして!!
まさかのなんとかなるらしいことが判明
技術書典6の配置は量子コンピュータで算出されます(嘘です)!
サークル参加の皆さんへのお願い ここまで読んでくださった方はおそらく気付いているかと思いますが、自動配置の精度には各サークルにジャンルのタグが適切に付いているか重要です。